MapReduce
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster
Phases Involved
Map Phase: Each worker node applies the "map()" function to the local data to generate intermediate key/value pairs and writes the output to a temporary local storage. A master node ensures that only one copy of redundant input data is processed.
Shuffle Phase: Worker nodes redistribute data based on the output keys (produced by the "map()" function), such that all data belonging to one key is located on the same worker node.
Reduce Phase: Worker nodes now process each group of output data, per key, in parallel.
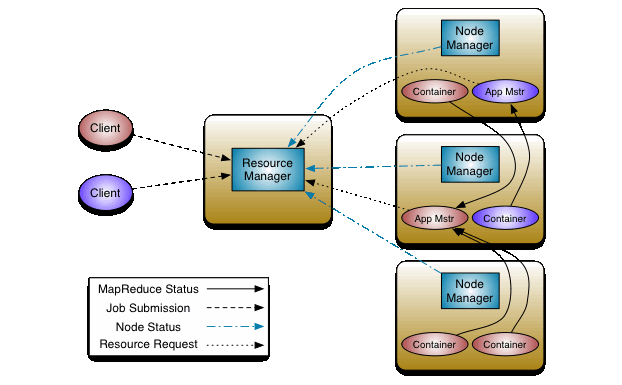
YARN Scheduler
YARN (Yet Another Resource Negotiator) treats each server as collection of containers (CPU + Memory)
Components
- Global - Resource manager
- Per server - Node manager
- Per application - Application master
Failures
Server failure
- Node manager heart beats to resource manager, If server fails RM lets all affected AM's know and AM's take action
- Node manager keeps track of each task running at its server, If task fails NM will restart it
- AM heart beats to RM, On failure RM restarts AM which then sync up with currently running tasks
Resource Manager failure : Use old checkpoints and brings up secondary RM
Slow servers
Keeps track of progress of each task and create backup of straggler task and consider it done when first replica of task is completed, Also called speculative execution
Locality
MR task tries to schedule task on machine that contain replica of corresponding input data