Statistical Learning
Suppose that we observe a quantitative response and p different predictors, . We assume that there is some relationship between and , which can be written in the very general form
Here f is some fixed but unknown function of , and is a random error term, which is independent of and has mean zero.
Why do we need to estimate
Prediction
In many situations, a set of inputs are readily available, but the output cannot be easily obtained. In this setting, since the error term averages to zero, we can predict using
where represents our estimate for , and represents the resulting prediction for .
The accuracy of as a prediction for depends on two quantities, which we will call the reducible error and the irreducible error. In general, will not be a perfect estimate for , and this inaccuracy will introduce some error. This error is reducible because we can potentially improve the accuracy of by using the most appropriate statistical learning technique to estimate .
Since is a function of , Even if we estimate very well we cannot reduce this error (Irreducible error).
Why is there an irreducible error?
This is because there can be unmeasurable variations and dependencies
Inference
One may be interested in the following questions
- Which predictors are associated with the response?
- What is the relationship between predictor and response?
- Can the relationship be summarized as linear or is it more complicated?
How to estimate ?
Parametric methods
We make some assumptions about
Then finding boils down to finding parameters
The potential disadvantage of parametric method is if the actual is too far from our assumption, then our estimations will be poor. This can be reduced by using more flexible models which may cause overfitting
Non-parametric methods
It estimates by using near by data points. Since we are not fixing , This is the advantage over parametric methods
Disadvantage in this method is it requires a large number of data points to get accurate estimate of
Supervised vs Unsupervised learning
Supervised learning is where you have input variables and an output variable and you use an algorithm to learn the mapping function from the input to the output.
Ex: Regression, Classification
Unsupervised learning is where you only have input data and no corresponding output variables.
Ex: Clustering
Assessing Model accuracy
Measuring the quality of fit
Mean squared error
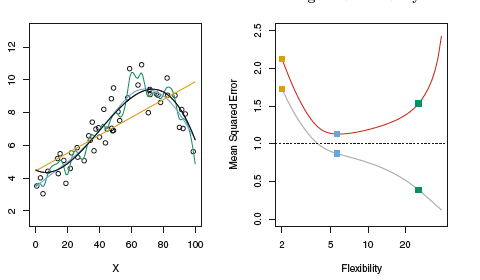
The red color in right side of the figure is test MSE and other one is training MSE
As the flexibility increases beyond the limit training error decreases but the test error increases, This is called overfitting
Bias-Variance tradeoff
Given as test data
From the above equation, In order to minimize test error we need to minimize bias as well as variance
Variance
Signifies the amount by which will change if we estimate using different dataset
In general more flexible statistical training methods will have high variance
Bias
Signifies the error that is introduced by approximating a real life problem
No matter how well we try estimate a real life problem using linear function, it won't be accurate. That implies linear regression will have high bias
In general more flexible functions will have low bias